数据模型设计¶
一个高效的数据模型能够很好的满足你应用程序的需求。设计一个文档数据结构最关键的考量就是决定是否使用 embed 还是 引用。
内嵌式数据模型¶
在MongoDB里面,你可以把相关的数据包括在一个单个的结构或者文档下面。这样的数据模式也叫做 “非规范化” 模式,它充分利用了MongoDB的灵活文档格式的功能。以下图为例:

Data model with embedded fields that contain all related information.
内嵌数据可以让应用程序把相关的数据保存在同一条数据库记录里面。这样一来,应用程序就可以发送较少的请求给MongoDB数据库来完成常用的查询及更新请求。
一般来说,下述情况建议使用内嵌数据:
数据对象之间有 “contains” (包含) 关系。 参见 一对一关系建模:内嵌文档模型。
数据对象之间有一对多的关系。 这些情况下 “多个”或者子文档会经常和父文档一起被显示和查看。请参见 一对多关系建模: 内嵌文档模型。
通常情况下,内嵌数据会对读操作有比较好的性能提高,也可以使应用程序在一个单个操作就可以完成对数据的读取。 同时,内嵌数据也对更新相关数据提供了一个原子性写操作。
然而, 内嵌相关数据到同一个文档内会很容易导致文档的增长。 文档增长会影响写性能并导致数据碎片问题。更多信息请参见 文档增长性。另外, MongoDB的文档大小必须小于16M。 超过这个大小的话,你可以考虑使用 GridFS。
当需要访问内嵌的数据时,你可以使用 dot notation 。 欲了解如何访问数组内数据或内嵌文档数据,参见 数组内数据查询 以及 内嵌文档数据查询 。
规范化数据模型¶
规范化数据模型指的是通过使用 引用 来表达对象之间的关系。
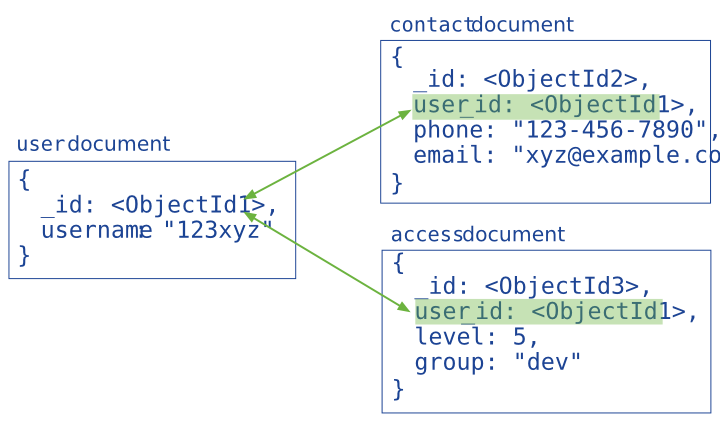
Data model using references to link documents. Both the contact document and the access document contain a reference to the user document.
一般来说,在下述情况下可以使用规范化模型:
当内嵌数据会导致很多数据的重复,并且读性能的优势又不足于盖过数据重复的弊端时候。
需要表达比较复杂的多对多关系的时候。
大型多层次结构数据集。
引用比内嵌要更加灵活一些。 但客户端应用必须使用二次查询来解析文档内包含的引用。换句话说,对同样的操作来说,规范化模式会导致更多的网络请求发送到数据库服务器端。
关于引用的例子,参见 一对多关系建模: 文档引用模式 。关于使用引用的树结构模型的例子,参见 树结构建模。