- 数据模型 >
- 数据模型设计介绍
数据模型设计介绍¶
MongoDB 的数据模式是一种 灵活模式 。关系型数据库要求你在插入数据之前必须先定义好一个表的模式结构,而MongoDB的 集合 则并不限制 文档 结构。这种灵活性让对象和数据库文档之间的映射变得很容易。 即使数据记录之间有很大的变化,每个文档也可以很好的映射到各条不同的记录。 当然在实际使用中,同一个集合中的文档往往都有一个比较类似的结构。
数据模型设计中最具挑战性的是在应用程序需求,数据库引擎性能要求和数据读写模式之间做权衡考量。当设计数据模型的时候,一定要考虑应用程序对数据的使用模式(如查询,更新和处理)以及数据本身的天然结构。
文档结构¶
设计基于MongoDB的应用程序的数据模型时的关键就是选择合适的文档结构以及确定应用程序如何描述数据之间的关系。有两种方式可以用来描述这些关系: 引用 及 内嵌 。
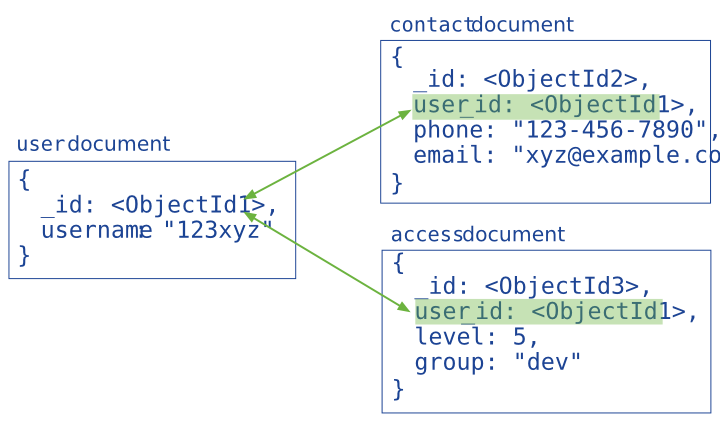

写操作的原子性¶
写操作在MongoDB里在文档级具有原子性 - 意即单个写操作不能针对两个以上的文档或者集合同时操作。由于一个有内嵌文档的非规范化,冗余数据模型包含了所有相关的数据,这样一个写操作就可以完成对一个对象所有相关数据的一次性插入或者更新。如果使用规范化,无冗余数据模型,那么一个对象的数据要分到多个集合里面的多个文档里去。这样一来就需要多个写操作来完成。这多个写操作作为一个整体是不具由原子性的。
但是要指出的是, 这种对原子性写操作利好的内嵌数据模型会限制应用程序对数据的使用场景。这篇文档 关于原子性 讨论了一些在模式设计时候 权衡数据模式的灵活性和原子性的要做的考量。
文档的增长¶
有一些文档的更新操作,例如在数组里增加元素或者增加一个新字段, 会导致文档的大小变大。如果文档的大小超出分配给文档的原空间大小, 那么MongoDB就需要把文档从磁盘上的现有位置移动到一个新的位置以存放更多的数据。 这种数据增长的情况也会影响到是否要使用规范化或是非规范模式 - 内嵌 。 文章 关于文档增长 讲述了一些比较具体的管理文档增长问题的讨论。
数据访问及性能¶
设计文档模型时,一定要考虑应用程序会如何使用你的数据。例如,假如你的应用程序通常只会使用最近插入的文档,那么可以考虑使用 限制集 。或者如果你的应用会做大量的读操作,那么可以通过加多一些索引的方法来提升常见查询的性能。
如需了解更多数据模式设计相关的内容,请参见 MongoDB特性和数据模型的关系。